
ImageBind: نموذج ذكاء اصطناعي يربط الوسائط المتعددة بطرق جديدة ومبتكرة
هل تحلم برؤية العالم من منظور مختلف؟ هل تتسائل عن طريقة عمل الذكاء الاصطناعي وكيف يمكنه استخدام الحواس المختلفة لفهم الأشياء؟ إذا كانت هذه هي تساؤلاتك، فأنت في المكان الصحيح! لأننا سنعرض عليك النموذج المتقدم للتعلم متعدد الوسائط “ImageBind”، والذي يدمج ستة وسائط متنوعة في نظام واحد دون أي مساعدة من البشر.
هذا النموذج يتعلم كيفية ربط الصور والنصوص والفيديوهات والأصوات والأشكال ثلاثية الأبعاد والحرارة والحركة بطريقة ذكية وابتكارية. بهذا النموذج، يمكن للآلات أن تفهم الأشياء، وتكشف عن خصائصها التي لا تظهر للعيان.
كنت في دردشة جميلة مساء الأمس مع الصديق محمد مزدور وهو من المختصين في الذكاء الاصطناعي ويواكب كل جديد في هذا المجال. اقترح علي كتابة مقال يخص نموذج “ImageBind” الجديد للتعلم الشامل الذي تطوره شركة ميتا حاليًا والذي سيكون متوفرًا قريبًا.
لقد أثار هذا الموضوع فضولي وشغفي، وأردت أن أنقل لكم بعض الحقائق عن هذا النموذج المتطور، الذي سيجعلنا ننبهر بالقدرات الخارقة التي يتمتع بها الذكاء الاصطناعي.
ما هو ImageBind؟
“ImageBind” هو نموذج جديد للذكاء الاصطناعي من شركة ميتا، يمكنه ربط البيانات من ستة أنماط في وقت واحد (الصور والنصوص والصوت والعمق والحرارة ووحدات القياس الحركية) “IMUs”.
وبفضل هذه القدرة، يمكنه التعرف على العلاقات بين هذه الأنماط، وتمكين الآلات من تحليل أشكال مختلفة من المعلومات معًا على وجه أفضل.
ومن المتوقع أن يزيد “ImageBind” من قدراته على نحو كبير في المستقبل وذلك بفضل الميزات المرئية القوية التي يوفرها نموذج “DINOv2”.
كيف يستفيد ImageBind من الصور للتضمين المشترك لبيانات الوسائط المتعددة؟
الإنسانية تتمتع بالقدرة على استيعاب المفاهيم الجديدة بسهولة من خلال الأمثلة البسيطة. فعلى سبيل المثال، يستطيع الشخص التعرف على حيوان ما بعد قراءة وصف مختصر له أو التنبؤ بشكل محرك سيارة غير معروف بناء على صورة واحدة.
وهذه القدرة ترجع جزئياً إلى الخبرة الحسية الكاملة التي تقدمها الصورة. أما في مجال الذكاء الاصطناعي، فقد يحول نقص البيانات الحسية المتعددة دون تعلم الطرائق المختلفة.
في الماضي، كان تعلم التضمين المشترك لجميع الوسائط المتعددة يتطلب جمع مجموعات هائلة من البيانات المقترنة، وهو أمر كان من الصعب تحقيقه. لكن “ImageBind” نجح في التغلب على ذلك من خلال الاستفادة من نماذج لغة الرؤية واسعة النطاق، وعمل على توسيع قدراته على التعلم عبر طرائق جديدة باستخدام الاقتران الطبيعي للصور مع بيانات الصوت والفيديو.
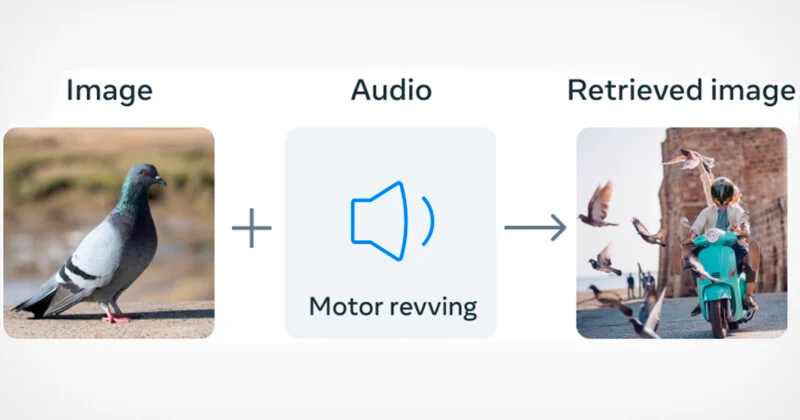
يعتمد ImageBind على ربط الصور وتكوين روابط بينها بطرائق متنوعة، مثل ربط النص بالصورة باستخدام بيانات الويب، أو ربط الحركة بالفيديو باستخدام مستشعرات “IMU” التي تم التقاطها من الكاميرات.
يستخدم “ImageBind” صورًا من الويب ليتعلم كيف ترتبط أنماط الوسائط المتعددة ببعضها البعض.
باستناده إلى البيانات المرتبطة بالصور، يمكن لـ “ImageBind” ربط الأنماط الست معًا. وهذا ما يجعل النموذج قادرًا على فهم المحتوى على وجه أفضل، ويتيح للأنماط المتنوعة التخاطب فيما بينها.
على سبيل المثال، “ImageBind” لديه القدرة على ربط النص والصوت دون مشاهدتهما معًا. بالإضافة إلى ذلك، يمكن لـ “ImageBind” بفضل أدائه القوي أن يخلق صورًا باستخدام الأصوات، مثل صوت الضحك أو المطر.
مستقبل نموذج ربط الوسائط المتعددة ImageBind
مع “ImageBind”، تصبح الإبداعات لا حدود لها. هذا النموذج الجديد يسمح لك بربط أنماط مختلفة مثل الصور والنصوص والأصوات وغيرها، ويعطيك نتائج مذهلة. تخيل أنك تلتقط فيديو لغروب الشمس على البحر، وتضيف صوتًا يناسب المنظر، أو أنك تصنع فيديو لحفلة رائعة. “ImageBind” يساعدك على إضافة أصوات خلفية تجعل تجربتك فريدة من نوعها واستثنائية.
Today we’re introducing ImageBind: a new AI model that can understand how images, audio, video, depth and motion all relate to one another to create a scene.
This creates new opportunities for creators in the future, like being able to take a video of a sunset and have the AI… pic.twitter.com/l1EfVMnsxs
— Meta Newsroom (@MetaNewsroom) May 9, 2023
هل أعجبك المقال شاركه مع أصدقائك لتعم الفائدة والمعرفة!
قد يهمك قراءة: منافس صيني جديد ل تشات جي بي تي من شركة Alibaba: فهل سينجح في ذلك؟





